A Bit of Evidence: a basic introduction to electronic evidence for non-technicians
(A version of this paper was presented at the ACFE European Conference in Brussels on 21st March 2016)
Electronic devices may well be the defining characteristic of our age. Actually, that assertion is not entirely accurate. The devices are not the defining characteristic in themselves. Our age is really defined by the uses to which such devices are put and our extreme level of reliance placed on them.
People from all walks of life are experiencing an unprecedented human interconnectivity that is impossible to either ignore or avoid: in study, at work, at home, at play, many, many communities are now integrated into multiple digital networks. At the time of writing[2] the latest statistics on Internet usage show that 3,345,832,772 people (i.e. 46.1% of the world’s population) have access to the Internet.[3]
The access and possibilities offered by digital technology are endless, but those same possibilities are just as open to exploitation by the criminal as they are helpful to the innocent user. In the specific area of fraud, computer devices can be used to communicate a fraudulent representation, to facilitate a fraudulent activity or to produce articles by which fraud can be perpetrated (for instance by producing counterfeit documents). Devices may also be the subject of the fraud (perhaps through the sale of fake devices or counterfeit software) as well as be used by criminals to identify and research potential victims and/or methodologies.[4] As such they undoubtedly provide a new and additional dimension in terms of means and opportunity. On the other hand, the use of digital devices also creates a new area for consideration in terms of investigation and evidence.
This paper will explore some basic concepts of electronic evidence, offering an introduction to the nature and challenges of such evidence while reviewing some of the key questions related to where electronic evidence may be found and how its integrity can be ensured. However, and by way of a friendly health warning, please bear in mind that electronic evidence is a vast area of inquiry and the information included here can be no more than a highly simplified and cursory account of the subject. It is offered purely as a starting point which curious readers can use to explore further through their own research and study.
Whilst the concept of evidence may vary slightly from jurisdiction to jurisdiction, this paper will adopt a wide definition and will refer to evidence as meaning anything that has a bearing or potential bearing on proving or disproving a fact relevant to an inquiry. It is not limited to the information adduced in court proceedings (or, indeed, formally documented in a case file given to a judge in a civil law jurisdiction). The term ‘electronic evidence’ refers simply to any evidence that is produced from or by means of an electronic (i.e. ‘digital’) device.
That said, we should perhaps start by reviewing one or two of the more unusual aspects of electronic evidence. Electronic evidence is:
- Essentially circumstantial;
- Often international;
- ‘Volatile’ and easily lost, contaminated or altered;
- At risk from electro-magnetic fields; and,
- Can be precisely duplicated (a characteristic that is very helpful for forensic examination as shall be seen presently).
These peculiarities will be discussed further below, but there is one aspect of electronic evidence that has a particularly important impact on an investigation or case: It can be considered trans-spatial.
Up until now, a criminal always had a physical connection to his or her crime and investigators were and are trained to look for something introduced into a crime scene, removed from it, or, changed in it. Electronic devices now provide the option for some crimes to be committed from vast distances. However, while there may not be a physical (or analogue) connection to the crime scene, there will be a virtual connection. In terms of electronic evidence, therefore, a more flexible notion of what constitutes a crime scene has certain advantages and assists in forming a more practical and helpful model of where such evidence may be found.
Assuming the proper legal justification and appropriate permissions or judicial authorisation can be secured, electronic evidence can be found in a huge variety of locations (some physical, many virtual) including:
- on the primary computer device itself;
- on secondary or auxiliary devices that connect to it (so-called ‘peripherals’);
- on types of portable devices or storage media;
- on devices that normally have no connection at all to the computer, but have some sort of computer memory;
- on other computers or devices that have been wired together to create a ‘network’;
- on a network somewhere outside of the immediate location; or,
- somewhere (anywhere in the world) via the Internet.
In addition to these sources, it is also always worth looking for other physical, non-electronic evidence that may refer to and/or corroborate electronic activity. For instance: people will often write down passwords and keep them ‘in a safe place’; there may be contracts or invoices indicating rental of on-line services or facilities; details of schemes and victims may be documented in hard copy; or, manuals on technical topics such as encryption or on-line anonymity may help to profile a suspect’s level of sophistication and the type of electronic evidence (and countermeasures) that may be encountered.
One word of caution when planning where to look for evidence, and this won’t come as a surprise to anyone: criminals like to hide things. Electronically this may involve the use of misleading file names or changed file extensions (e.g. renaming a suspicious looking file such as ill-gotten_gains.xls with an innocuous sounding name like Holidaysnaps.jpg), or the slotting of one file inside the outer shell of another (using something called an alternate data stream[5]). Less exotically, it may just mean hiding things physically in unusual covers. Does that DVD box on the shelf really hold a copy of a popular TV show?
If this sounds like there are potentially endless locations in which electronic evidence may possibly be found, then you have already started to grasp the idea. The good thing is that criminals don’t normally avail themselves of the full range of options open to them. In fact, they often unwittingly expose themselves and provide incriminating evidence by being just as promiscuous in their use of technology as everyone else.[6]
Here are just a few examples of locations where devices with electronic evidence may be found. Many of them are obvious, some are physical, others are virtual.




Two terms here probably warrant some additional explanation: Server and ISP.
Server:
A server can be thought of as a machine that runs software used by other computer devices connected to it in a network. According to one 2013 estimate, the Internet incorporates more than 75,000,000 servers.[7]
ISPs:
ISP stands for ‘Internet Service Provider’. An ISP is a company that provides its customers with facilities and access to the Internet.
Let’s take a look now at some of the mechanics of computer memory.
A bit of memory
Most people these days have heard of the ‘bit’ and its bigger sibling, the ‘byte’. The bit is the smallest particle in a computer memory, like one brain cell or a single atom, and is a contraction of the words Binary and digIT. And there you have at once the essence of electronic evidence and something of its frustration. ‘Binary’[8] means there are only two options and computers[9] (perhaps not having 10 fingers like us) can only count in twos. This is because a bit can only exist in one of two states: on or off; yes or no; 0 or 1. So, while for most of us, 1+1 = 2, when a computer adds 1+1, it counts 10. Now, if in reading that 10, you thought ‘ten’, then you were not thinking like a computer. In the binary system of counting 10 represents what we call two. The zeros and ones in a computer memory are combined in a computer brain in different meaningful patterns based on groupings of eight bits. With one bit, you only have two options, 0 or 1, but add another bit and the possible number combinations becomes four:
00
01
10
11
Add a third bit and the possible patterns now doubles to eight.
000
001
011
111
110
100
101
010
Add a fourth and the combinations double again … and so on. And that is why computer memories are always expressed in factors of eight. Every group of 8 bits is called a byte. Still with me?
Given that a computer processes everything in zeros and ones, we need to process those digits into something more familiar and easier for our analogue brains to understand.
We have seen that a byte is made up of 8 bits. Well, using a system called ASCII (American Standard Code for Information Interchange[10]), it takes a minimum of 8 bits (or one byte) to represent a letter or number based on the Latin alphabet. Thus:
0100010101110110010010010100010001000101011011100100001101000101
is how the word ‘evidence’ appears to a computer using ASCII. Letter by letter we can break it down like this:
| E | 01000101 |
| V | 01110110 |
| I | 01001001 |
| D | 01000100 |
| E | 01000101 |
| N | 01101110 |
| C | 01000011 |
| E | 01000101 |
Latin characters have reasonably simple and straight forward designs, but the one byte:one letter relationship doesn’t quite work where forms of writing are more artistic and complex. Languages like Arabic, Chinese, Thai or Armenian use instead another system called ‘Unicode’[11] which, depending on the version, can require between 2 and 8 bytes (i.e. 16 and 64 bits) or more to represent each character.
This binary idea has also dictated the design and engineering of the various mechanisms used to store data. Up to today, the main method for storing computer memory has been based on magnetism. More likely than not, your computer will contain something called a hard disk drive. The hard disk[12] in question will be covered by a layer of metallic particles each of which can be magnetised or demagnetised. A small arm hovers across the surface reading or changing the magnetism in the particles. Think of an old fashioned gramophone with vinyl discs.[13] The gramophone has a device called a pickup with a needle that runs along a groove in the disc. At the bottom of the groove there are a series of tiny bumps that are converted into vibrations in the air that we perceive as sound. A computer’s hard disk rotates at between 4,500 and 15,000 RPM, which is significantly faster than the 33 RPM of a Long Playing Record, and, as the arm travels across the surface of the disk, it reads the arrangement of magnetised particles as data. If a particle is magnetised, it is read as a 1, if it is not, then it counts as a 0.

Inside a Hard Disk Drive
These days computers may contain an alternative type of memory device called a solid state drive (i.e. there are no moving parts). These drives consist of thousands of tiny transistors (switches) that can be either turned on or off. If a transistor is on and conducting an electric current, it counts as 1, if switched off, it counts as 0. Solid state drives can cram a lot more bits into a given space and can, therefore, also hold much more information. They work faster, are less susceptible to physical shock and produce much less heat than the mechanical hard disk drives, but they are also more expensive and have a limited life span in terms of the number of times data can be saved.
The maximum number of bits that can be currently crammed into a given surface increases roughly in accordance with something called ‘Moore’s Law’. Back in 1975, Gordon E. Moore, co-founder of the microprocessor manufacturer Intel, predicted that the number of transistors packed into a given unit of space will roughly double every two years. So far his prophecy has held true. The evidential implications of this exponential evolution in storage capacity are substantial. For instance: investigations now potentially involve a lot more memory and the forensic procedures consequently require more time, more effort and are significantly more costly.
But this is as nothing when compared with the evidential implications of so-called cloud storage. As users switch from keeping data locally to storing it in a remote and often non-specific location, the challenges of (a) finding the data; (b) obtaining the necessary cooperation and permissions to retrieve it; and, (c) the lead-in times required to obtain it, become ever more complex and onerous. When data is stored in the cloud, it does not stay in one place. Companies offering and managing cloud storage regularly move data around between server farms for operational and security reasons. That means evidential or suspect data may be located in this jurisdiction today and that jurisdiction tomorrow. Current methods of international legal cooperation do not work that quickly.
Putting such potential frustrations aside, let us consider, instead, a particular and useful aspect of the way memory is arranged on a hard disk drive.
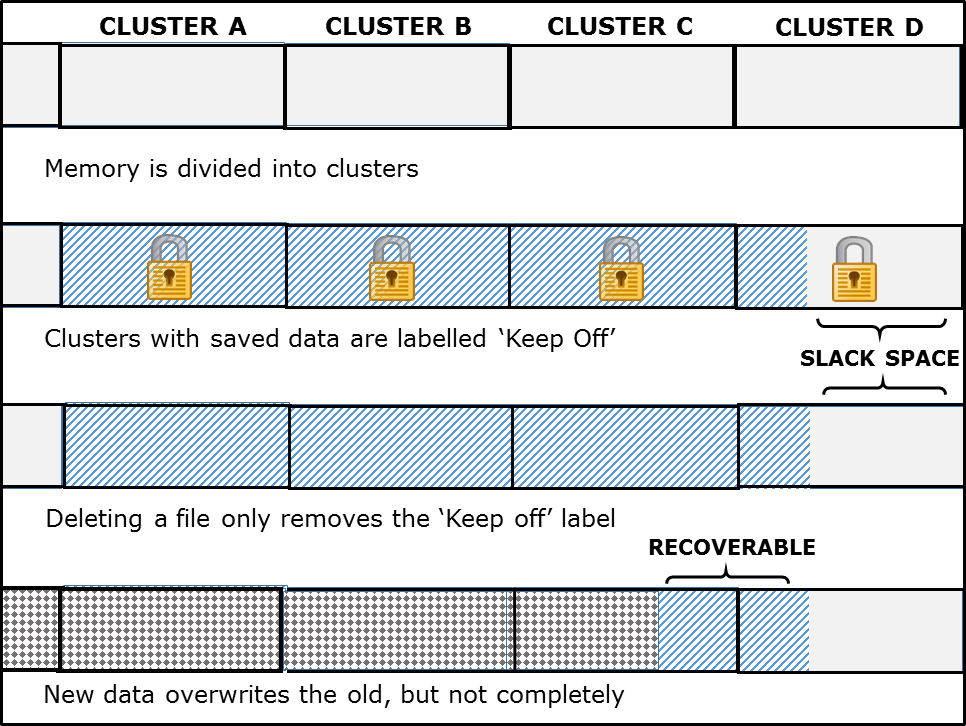
I hope I have managed to conjure in your mind the mental image of ‘tracks’ recorded on the surface of the disk, just like with old fashioned LPs. Let’s develop that picture just a little. Those who belong to my (less technologically integrated) generation will remember LPs had sleeve notes that gave information (the ‘meta-data’[14]) about each track: the position of a track on the disc, what it was called, how long it lasted etc. Computer file systems have a similar arrangement for noting where a file is located on the disk and certain other important details about it. For instance, in order to prevent your file from being recorded over, the area on the disk where you saved your file is labelled with a special ‘keep off’ flag. If you then decide to delete that file or click and drag it to the Recycle Bin on your computer, the data remains in situ occupying the same space on the disk. The only change is that the ‘keep off’ flag is removed. In fact the data sits there until other data is recorded (or ‘written’) over it. This means that deleted files can often be recovered from a disk even though the file cannot be seen in the Documents folder. Even if that part of the disk is ‘overwritten’, it may well be possible to recover fragments of the previous file because two files are never exactly the same size and the new file may not be the right size and shape to eclipse the old completely.
This leads us nicely to discuss the concept of ‘slack space’ which can also be helpful in finding fragments of a previously deleted file. Think of the tracks on the disk as being subdivided into thousands of little boxes called sectors. The sectors are banded together into groups or ‘clusters’ that have a maximum capacity.[15] When a file contains more data than one cluster can hold, it spills over into another (which may or may not be physically next to it on the disk). Now, because the system can only assign one file or part of a file to a cluster, if the overflow cluster is only 10% full, the other 90% remains empty as ‘slack space’. The good news is that any fragments of data left over from an earlier file in that empty 90% are recoverable.
Just by way of comparison, it might be interesting to know that data is stored on CDs, DVDs and Bu-Ray discs in a slightly different way. Zeros and ones on these discs are recorded in the form of tiny bumps on the surface (called pits) that are read by a laser beam in a way not dissimilar to the needle in the grooves on vinyl records mentioned above. In order to record data on the disc, the laser ‘burns’ the pits onto the surface.
A bit of anonymity
If you hang around computer circles long enough you are sure to hear the phrase, ‘On the Internet, no one knows you’re a dog’. It highlights a major challenge in respect of the Internet: Attribution.[16] In terms of fraudulent representation, this image is also a useful point of departure for a discussion on anonymity. Taking for granted that the person on the other end of your Internet communication is both what and whom they claim to be displays a serious lack of computer savvy. For example, how do you know if your email or chat correspondent is honestly:
- trying to liberate a large fortune lying in the unclaimed bank account of a deceased despot and is willing to pay you a percentage?
- peddling rolex watches at half the price of the genuine article?
- selling prescription medicine that is guaranteed not to have been adulterated with chalk powder or cyanide?
- offering love and companionship and not looking to soak a lonely heart of his or her life savings?
- requesting your pin number to check your security because your bank account has really been compromised?
The fact is you don’t. Where the Internet is involved, establishing with sufficient certainty a suspect’s identity is one of the biggest challenges in electronic evidence. The first step is to identify the computer or device used by him or her.
Remember, there are already 3,345,832,772 Internet users in this particular haystack. Fortunately, the architecture of the Internet and the way it functions help enormously. Because of the way the Internet works, any device connected to the Internet must register its connection with an Internet Protocol (IP) address. This IP address is unique and allows messages zipping around the labyrinth of the Internet to know where they are supposed to end up. In the real world, you will know that a protocol is a set of standards and a prescribed way of doing something. For instance, in my country, the UK, protocol dictates that you must not speak to HM the Queen unless she speaks to you first… and woe betide you if you dare actually to touch Her Majesty! In computer terms, a protocol is also an agreed way of doing things and, in terms of the Internet, the Internet Protocol dictates that you have to connect with an IP Address.
IP addresses can be either static or dynamic. A static IP address means it is assigned by an ISP to someone for their exclusive use and is normally provided only to customers that require a permanent presence on the Internet. Most of us, however, are assigned dynamic IP addresses that are ours only for the length of time we are logged on. The millisecond before we log on, the IP Address is probably being used by someone else. The millisecond after we log off, it is immediately available to be reassigned to another customer. This means, unless you get the timeframe precisely right when you request data from an ISP, you will end up targeting an entirely innocent third party.
There are two versions of IP address. The long-standing IPversion4 (IPv4) is very (very) slowly being replaced by IPversion6 (IPv6) because its limited number of permutations cannot satisfy global demand. The more complex structure of IPv6 should, eventually, provide enough addresses to go around. For now IPv4 addresses remain by far the most common. An IPv4 consists of 4 sets of numbers between 0 and 255 with separated by a dot like this:
74.125.206.106
If you put this number in the address field of your browser, you should get www.google.com.
In the usual run of things, any Internet activity will leave an audit trail indicating the IP address of origin and, finding the name of the user to whom that address is assigned, is relatively straightforward. You have only to enter it into any one of the many IP lookup sites on the Internet. If it is a static address, the lookup site will immediately return the name of the company involved. If it is a dynamic address, it will return the name of the relevant ISP. Once you know the ISP, you can find out to whom that address was assigned at the relevant time by applying to them.[17]
If only it were always that simple! Any criminal with an ounce of technological awareness will know that there are multiple ways to mask an IP address.
The simplest way would be to go to a public place and connect to a Wi-Fi hotspot: bars, restaurants, shopping malls, airports all offer such opportunities. There is also a technique called ‘war driving’ in which miscreants and malefactors roam the streets until they find an unsecured Wi-Fi signal on which to prey. When such techniques are employed, it is still possible to identify a particular computer on a network by its identifying number called the Media Access Control (MAC) address. MAC addresses are unique and are assigned by the manufacturer. Although they can’t be changed, a device can, unfortunately, be made to transmit a phoney MAC address. Identifying a MAC address may help establish patterns of behaviour, but since they are not registered against names in the same way as IP addresses, they really only come into their own when investigating inside a private network or the device has been seized and you need to check where it has been used.
The investigative value of IP addresses, as well as their limitations, are well illustrated by the case of Bobby Alexander. In California, March 2015, Alexander allegedly burgled an apartment and stole a Smart TV on which the victim had installed the Netflix movie service. It is reported that after a few days the victim realised her Netflix account was being used by someone else. She alerted the investigators who traced the IP address and raided the location indicated by the ISP only to come up empty handed … until the innocent occupiers at that address happened to mention that they allowed their next door neighbour to piggyback on their Wi-Fi signal.[18]
Slightly more involved than using somebody else’s Internet connection, but not much, is connecting to the Internet through a proxy server. I am sure you know about proxy votes: You give the permission and authority to someone you trust to go to the polling station and cast a vote on your behalf. That trusted person is acting as your ‘proxy’. A proxy server is a machine that stands between you and the Internet and represents you on the network. As far as the rest of the Internet is concerned, the IP address of that proxy is your identity. Both free and commercial proxy services are available and easy to install.
There are, of course, also services that provide more comprehensive anonymity when surfing the net (and will also provide access to the hidden sites of the Dark Net): The Onion Browser (TOR) network and I2P services are highly interesting, but out of scope of this paper.
Once you have identified a suspect device, there are certain other important matters to consider. In order to establish opportunity, you need to prove who had access to that device and who was using it at the relevant time. One way is to ask an examiner to check the time line of suspect behaviour against log-in IDs in the computer’s system memory. For instance, many programs or online accounts require usernames and passwords and access to such accounts during your suspect timeframe can be seen as prima facie evidence of the identity of the user. Looking at other activity around the relevant time can also provide good evidence of identity (for instance, where a suspect uses a personal blog, or posts to a social network or shops online using a personal credit card). Once again you will need to be absolutely sure of the actual times involve. Be aware that devices may not have been set to the correct time and there can be substantial drift between the internal clock time and that used by a server or web service. Time zone differences are also important in this regard.
A bit of a hurry
We have already noted that electronic evidence is volatile. Every time a computer does something (either because you push a button or because of some automatic process) the computer memory will be changed in some way. Supposing you inadvertently start a process in the computer that results in data vital to your case being overwritten? Suppose the suspect then claims that his or her defence has been irrevocably lost because of clumsy actions at the scene?
Another unusual characteristic of digital data is that it can be altered so convincingly that sometimes you can’t trust the evidence of your own eyes.
Take, for instance, the case involving UKPC, a large company that provides outsourcing services for the enforcement of private parking in the UK. In September 2015 the company reportedly admitted that ‘some employees’ had been forging time stamps on photographs used to support the issuing of parking penalties.[19]
Cases like this demonstrate how the confidence of the court can and should only be assured through the application of very strict procedures of validation and verification. But first, we need to understand something about the difference between ‘live’ and ‘dead’ data acquisition.
Where a machine is on and functioning at the time of data acquisition, it is said to be ‘live’ (and, conversely, devices that are switched off are called ‘dead’). Live data acquisition happens in real time at the scene and is a highly specialised function that has become increasingly important. Once upon a time, any device found to be switched on during a search would have had its plug pulled. Today, that is not considered acceptable.
Consider the Random Access Memory or RAM. The RAM is similar to the pre-frontal cortex of your brain in that it is the part of the machine that contains the memory for whatever activity is going on for the time being, but forgets everything once it is no longer useful. If you have ever had a program shut down unexpectedly and lost the document on which you were working, it is because you didn’t save it to the long term memory and the RAM has forgotten it. When you activate a program or start working on a document, the RAM brings it out of the filing cabinet and brings it to the forefront of operations (i.e. your desk or workspace) so the program can run faster and more efficiently. Modern computers are likely to have RAM with a capacity of 8-16 GB. This size allows a computer to juggle several complex tasks at the same time, but it also means that a lot of valuable information can be lost when the RAM is shut down unexpectedly.[20] That valuable information can include things like current links to the Cloud or passwords or files that are being worked on at the time. Of course there are software tools that will allow you to capture the live data being processed by the RAM, but a high degree of care is required. A false step here and any evidence will be contaminated and invalidated. One basic and common precaution is to connect something called a writeblocker[21] when downloading anything from a live device. This acts as a one-way valve allowing data to flow out of the device, but preventing anything flowing into it. And, of course, as with any forensic discipline, every action must be properly documented and objectively justifiable.
Servers on company or corporate networks, or servers that also host data from innocent third parties, will need special care and specialist attention to ensure a minimum of commercial disruption and prevent collateral intrusion.
As devices have become increasingly portable and smaller in size, they have become more reliant on and accessible through wireless networks. Mobile telephones may connect to the phone company’s antenna even though dormant. Any risk that someone could access the device remotely and delete the evidence needs to be negated by shielding it from rogue signals. This can be done by placing the device in a Faraday bag (named after the physicist and electricity pioneer, Michael Faraday). A Faraday bag has a lining that shields the contents from electro- magnetic fields. This same principle is now being quite commonly employed in personal wallets and purses in order to protect contact-less bank cards, but shoplifters have for years lined an ordinary shopping bag with aluminium foil to block the radio tags on the items they steal.
A bit of a hash
Once a computer drive or memory storage device arrives in the forensic lab, the last thing that happens is that the evidence is extracted. The first thing that happens (after the relevant chain of custody formalities have been completed, of course,) is that the drive is cloned or ‘imaged’. One of the most interesting characteristics of electronic evidence is that it is possible to duplicate it exactly and without any replication error. The clone (also known as a bit-by-bit or bit stream image or copy) duplicates each and every zero and one on the original disk. Traditional forensic science involves examining samples physically taken from the scene. Digital forensic examination works only on copies of the data with the original stored safely as a control in case of dispute. But how can a court be satisfied that the cloned image, and therefore the evidence drawn from it, is indeed exact?
The answer is through the use of a hashing algorithm. This is a kind of equation that, when applied to the binary numbers on a drive, produces a unique result called a ‘hash value’. There are several algorithms used for this purpose (most popular of which are the Message Digest (MD) 5 and the Secure Hashing Algorithm (SHA) 1). In the forensic lab, the examiner will ‘hash’ both the original drive and the duplicate and make sure the values match.
By way of example, let me take the title of this paper: A Bit of Evidence. When I run it through the MD5 algorithm, I get:
A Bit of Evidence
Hash Value: fb1fd4490a3cf45fcc1c3ac9c631ea10
If I try the same thing again, but use a lower case e in the word Evidence the result is entirely different:
A Bit of evidence
Hash Value: 1900c409c309bb6b54652a6a65ceb05c
In evidential terms, if the duplicate drive has just one 0 or 1 out of place then a completely different hash value will result. This allows a court to be satisfied beyond a reasonable doubt that the original and the cloned image are exactly the same.
Let us now have a quick look at just a few of the kinds of evidence that might be found (or might fail to be found) on a computer.
A bit of browsing
Once upon a time, if you wanted to find out some information about some obscure subject or other, you would trot off down to the local library, dig out the reference in the card index and/or browse along the rows of book shelves until you found a likely-looking tome. How times have changed! Your favourite search engine and Internet browser now provide access to literally millions of indexed knowledge files and can retrieve specific information in a matter of seconds.
What might come as a surprise to some people is just how much information about you and your browsing habits are preserved on your computer as well as on the web server. It certainly came as a surprise to Mr. Mohammed Ammer Ali who was found guilty of trying to buy enough ricin to kill 1,400 people.[22] One might have thought that, as a computer programmer, Mr. Ali would have known better. The prosecution was able to show he had googled ‘abrim v ricin[23]’ and used Yahoo on his smart phone to search for ‘home made cyanide and ricin’ on his computer and searched for ‘what poison kills you quick, is foolproof, easily found/made, easily concealed and hard to detect post mortem’. Fortunately he tried to buy the poison from an undercover FBI agent (remember no one knows who or what you are on the Internet) and he is currently serving eight years imprisonment.
By default, browsers not only log the times and titles of all the websites you visit, but also keep copies of the websites in a kind of memory called the cache. The cache helps speed up the loading of the web pages you frequently use by keeping a copy of the page from your last visit. If you are using Mozilla Firefox or Chrome as a browser, try typing about:cache in the address bar at the top and see what happens.
But browsers not only log the websites you accessed, they may also keep your passwords and log-in details – always in the spirit of a ‘better user experience’ of course. If you were to look at someone’s computer and find that these locations on the computer were empty, then you might conclude that your suspect is both computer literate and security aware … or possibly that s/he has something to hide. However, even if such information is missing locally, it is always possible to retrieve such details from the suspect’s web server which will normally be outside of their control, but just as helpful.
A bit of mail
For the last 20 years or so, the number of paper letters sent with a stamp through the national postal services has been decreasing in favour of the electronic equivalent, the e-mail.[24] Emails have also become an important vehicle for perpetuating fraud – whether through the message they contain or because of a toxic attachment. Letters sent by ‘snail mail’ will usually be enclosed in an envelope with the destination address, sometimes a sender’s address, a stamp and usually a post mark that shows where the item entered the postal system and when. If these letters pass through different national postal services, the new national service will usually add another postmark. In this way, the routing of the letter can, at least in part, be reconstructed.
Emails can also show detailed information about the origin, destination and routing, but you have to know where to look. This information is contained in an unseen area of your email called the header.[25] In the header (which you should read from the bottom up) you can find the IP address of the sender, the unique id number given to that message (the ‘message id’), the different servers on the Internet through which the message passed as well as the exact timings involved (including an indication of the time zone where the server was located). Unfortunately many of these details can also be altered or ‘spoofed’.
If you have a decent spam[26] filter on your email system and open your junk mail folder, passing your cursor over the address of the sender will often reveal a different sender to the one named on the ‘envelope’. This often happens where the originating email comes from a computer that has been enslaved as part of a botnet. The legitimate owner will not even know his or her machine is being used in this way.[27]
In order to send an email, the sender has to belong to an email hosting service. The common, free, services are well known (Outlook, Hotmail, Gmail, Yahoo etc.), but there are also countless email hosting services that offer differing layers of encryption and anonymity (see for instance: Hushmail, Protonmail, neomailbox, anonymousspeech). Unfortunately, it is not difficult to create an email account using false details and often the ways of checking identity are simple to overcome. Fraudsters do it all the time.
Recently there was a high profile case of a hoax bomb threat against state (public) schools in New York and Los Angeles. The email service (cock.li) used for sending the threat belongs to a US national, now based in Romania, who ran the email software on servers owned and operated by a company in Germany.[28] He apparently used a Germany company because he thought the data protection controls were strong. Unsurprisingly the German authorities seized the data from these servers, but prosecutors in New York also issued the owner of cock.li, a certain Vincent Canfield, with a subpoena duces mecum (this is a kind of summons demanding that the recipient turn up at a given time and place and produce specified physical or documentary evidence). Mr. Canfield has placed an image of this subpoena online[29] and it provides a handy checklist of the sort of information that may be available from any provider of services on the Internet:
- Account holder names
- Account holders addresses
- Social security numbers
- Billing addresses
- Phone numbers
- Contact names
- Postal code
- Country
- Associated email address(es)
- Date of creation
- (If applicable) Time of closure
- All IP addresses and each login
- MAC Addresses for router and any devices used
- Lifetime history of these accounts
- Transactions History: times, dates, amount, types
- Financial instruments
A bit hidden
I already mentioned above some ways in which data files may be hidden on a computer, but I would also like to mention two other interesting areas where evidential data might be found, but which are not immediately obvious: EXIF data and steganography.
EXIF stands for Exchange Image File Format and relates to pictures taken with digital devices. It is another example of a file’s metadata being stored by default without the user being consciously aware of it. The data includes technical details such as the focal length and shutter settings and whether the image has been photo-shopped, but it also contains some really useful evidential information such as the type and model of the device, its serial number, the date and time the picture was taken, and, if enabled, it will even show the GPS coordinates. So, for any case where the provenance and circumstances of an image is at issue, EXIF data can be quite useful. Do beware, though, the accuracy of any user defined data such as the timestamp.
The art of Steganography has been around ever since writing was invented. The word comes from the Greek steganos (meaning ‘hidden’) and refers to hiding one message inside another. These days using invisible ink or microdots is less common. Instead, software (both free and proprietary) is readily available that can seed secret data amongst the code of another file by subtly changing a few zeros and ones here and there. The changes are imperceptible to human senses and the doctored file (which can be of any type: document, music, video or image) will have the same total number of bytes or file size as the original. Of course, if you have the original available, then the hash value will be different and, if you find a steganography program on a suspect’s device, that may lead you to draw certain conclusions. To recover the hidden file, you would need to know both the specific software used to encode it as well as the password assigned by the person who encrypted it.
A bit of software
This paper has mentioned several times the need for appropriate software tools and there are a number of tools available for retrieving evidence from the inner recesses of a computer. Leading names in proprietary software are Accessdata (the Forensic Toolkit), Guidance Software (EnCase), and Cellebrite (for mobile or cellphone forensics). These are engineered to a high quality and have an established track record of delivery in criminal justice, but they are also expensive and entail significant onward investment with each new version and update. This may not be a problem for large organisations or well-funded agencies, but, where the financial situation is less generous, there are also highly respected free and open source tools which provide a more economical solution (including in particular the Sleuthkit, Volatility and Wireshark and a whole host of other free and paid for programs).
The really important things to remember are:
- There is no ‘evidence button’ and the skills and training of the examiner are paramount;
- If not properly primed with the right questions, the work of the forensic examiner will be less effective;
- No one software tool can find everything;
- Dual verification of a finding with a second tool is good practice;
- The examiner must be able to explain what the tool does and why it was used;
- Evidential findings have to be reduced to a transparent, jargon-free report that can explain and demonstrate those findings effectively to a non-expert audience;
- Colleagues and counterparts in other parts of the world, if they even possess a digital forensic capacity, may be using different software (or different versions of the same software) with very different operating procedures.
A bit of a conclusion
For those involved in criminal justice, which is an area of professional engagement considered far more conservative and traditional than most, a lack of familiarity with new technology can be not only highly intimidating, but also embarrassing. Such sensitivities are only heightened by the speed with which technology is evolving. Standards of knowledge and techniques that were satisfactory a decade ago are now dangerously inadequate. Where crime scenes were once specific and geographically limited to the immediate vicinity of a crime, the search for electronic or digital evidence now has the potential to extend across continents. Whilst computer data is often stored locally, it is increasingly stored through the Internet in some distant location of which even the computer user may be unaware.
In the same way that it is unnecessary to know the precise science behind DNA or gas chromatography, an advanced technical understanding of electronic evidence is not required for everyone involved in criminal justice. However, and at the very least, an awareness and appreciation of the context, nature and value of electronic evidence is now a prerequisite for anyone hoping to detect criminal behaviour or to build an effective case file. This paper has provided just a few of the more essential insights necessary even to begin to discharge the duty of care related to dealing with electronic evidence. It is a start and nothing more …
Some further reading
Books:
Bryant, R. and Bryant, S. (2014) Policing Digital Crime (Ashgate)
Casey, Eoghan (2010) Handbook of Digital Forensics and Investigation (Elsevier Academic Press)
Holt, T.A. et al. (2015) Cybercrime and Digital Forensics: An Introduction (Routledge)
Mason, S. (2012) Electronic Evidence (LexisNexis Butterworths)
Sammons, J. (2012) The Basics of Digital Forensics (Syngress)
Shipley, T.G. & Bowker, A. (2014) Investigating Internet Crimes (Syngress)
Reports:
Koops, K. and Goodwin, M. (2014) Cyberspace, the cloud and crossborder criminal investigation available at
www.gccs2015.com/sites/default/files/documents/Bijlage%201%20-%20Cloud%20Onderzoek.pdf
7safe (Date Unknown) ACPO Guidelines on Computer Based Electronic Evidence v4 available at www.7safe.com/docs/default-source/default-document-library/acpo_guidelines_computer_evidence_v4_web.pdf
Websites:
http://www.coe.int/en/web/cybercrime
http://www.computerforensicsworld.com/
http://www.digital-detective.net/
https://en.wikipedia.org/wiki/List_of_digital_forensics_tools
https://forensiccontrol.com/resources/free-software/
http://www.forensicsciencesimplified.org/digital/how.html
https://www.ncjrs.gov/pdffiles1/nij/199408.pdf
http://www.nij.gov/topics/forensics/evidence/digital/Pages/welcome.aspx
http://www.nist.gov/oles/forensics/digital_evidence.cfm
[2] December 2015
[3] www.internetworldstats.com: Internet penetration by continent (15 November 2015): Africa 28.2%; Asia 40.0%; Europe 73.5%; Middle East 52,2%; North America 87.9%; Latin America/Caribbean 55.9%; Oceania/Australia 73.2%
[4] One 2011 survey, for instance, found that 78% of burglars use social networks to research their targets: www.digitaltrends.com/social-media/nearly-4-out-of-5-of-burglars-use-social-netowrks-to-find-empty-homes/ accessed 12th December 2015
[5] Hiding data in an Alternate Data Stream (ADS) is a possibility with windows file systems. An ADS is not revealed by a normal document search, but can be discovered using specialist software tools. It is a little like putting a second card inside the envelope when you post a birthday card) or the way in which stereo sound signals are recorded on different parallel channels. This characteristic was previously used, for instance, by British police officers when recording suspect interviews on cassette tape. One track carried the interview, the other the time signal.
[6] See, for instance: http://www.forbes.com/sites/kellyphillipserb/2015/04/16/10-notorious-tax-cheats-rashia-wilson-self-styled-queen-of-tax-fraud/#2715e4857a0b6091bb30424e; https://www.youtube.com/watch?v=tEkVbqk_kkE; http://www.telegraph.co.uk/news/uknews/crime/11414610/Wanted-criminal-who-openly-taunted-police-on-Facebook-is-caught.html; http://www.hngn.com/articles/133898/20150927/bank-robber-caught-posting-pictures-facebook-stolen-cash.htm ; http://www.cbsnews.com/news/dc-man-announced-theft-on-victims-facebook-page-gets-44-months-in-prison/;
[7] http://www.whoishostingthis.com/blog/2013/12/06/internet-infographic/
[8] Occasionally you may download a program and a little window pops up warning you that this is a ‘binary file’. In this case, the word binary means the file is in binary code.
[9] I use ‘computer’ here to include any electronic device that has the capacity to remember things.
[10] www.ascii-code.com
[11] www.unicode.org. With each Unicode character needing up to 48 bits, you can imagine how many zeros and ones are needed to write down even a simple text. To make the numbers a little more manageable, computer experts convert these huge numbers into a base16 notation called ‘hexadecimal’, but that is not something we need to consider here.
[12] In fact there will be more than one disk or ‘platter’ stacked on top of each other. For the sake of simplicity, I am referring to just one.
[13] I use the spelling ‘disc’ to indicate vinyl records and to distinguish it from the type of disk that is a component on a computer.
[14] Metadata is normally defined as ‘data about data’. It describes the technical characteristics and specifications of a file.
[15] A sector is the smallest area in memory that a computer can read. A cluster is the smallest area in memory that can hold a file.
[16] i.e. attributing with certainty and confidence the real origin of a computer signal.
[17] Paste this into your Internet browser and it will show you your current IP address: http://whatismyipaddress.com/ip-lookup
[18] http://www.nydailynews.com/news/crime/calif-thief-traced-victim-netflix-cops-article-1.2159220
[19] http://www.telegraph.co.uk/news/uknews/crime/11858473/Parking-firm-UKPC-admits-faking-tickets-to-fine-drivers.html
[20] By way of comparison the whole Apollo Guidance System that saw Apollo 11 get to the moon and back in 1969 only had a 64 Kilobyte memory. Source: http://www.computerweekly.com/feature/Apollo-11-The-computers-that-put-man-on-the-moon
[21] A writeblocker can be both hardware and software.
[22] http://www.theguardian.com/uk-news/2015/jul/29/liverpool-man-who-ordered-breaking-bad-style-ricin-delivery-found-guilty
[23] Two deadly toxins
[24] Although email now seems to be losing ground to other forms of communication like instant messaging.
[25] In Outlook or Hotmail, go to the dropdown menu in the blue menu bar marked <…> and click on <message source>. In gmail, click on the downward arrow in the top right hand corner of your message and click on <view original>
[26] Anyone who has ever had an email account will know the curse of unsolicited bulk e-mail or ‘spam’.
[27] Botnets are roBOT NETworks. They consist of an army of machines infected by malware and being operated remotely by a criminal.
[28] Mr. Canfield moved the data for his email service to Iceland in January 2016 after the German authorities seized his second hard disk.
[29] https://cock.li/transparency/2015-12-15-subpoena/00-2015-12-15-141118-subpoena.png